图 5 - 唤醒到回复完整时序
用户喊"你好小智,今天天气怎么样?"——从声音进入麦克风到喇叭说出"上海今天小雨",整个过程哪些组件参与了?什么顺序?
如果上方图无法显示,点这里看 PNG 版本
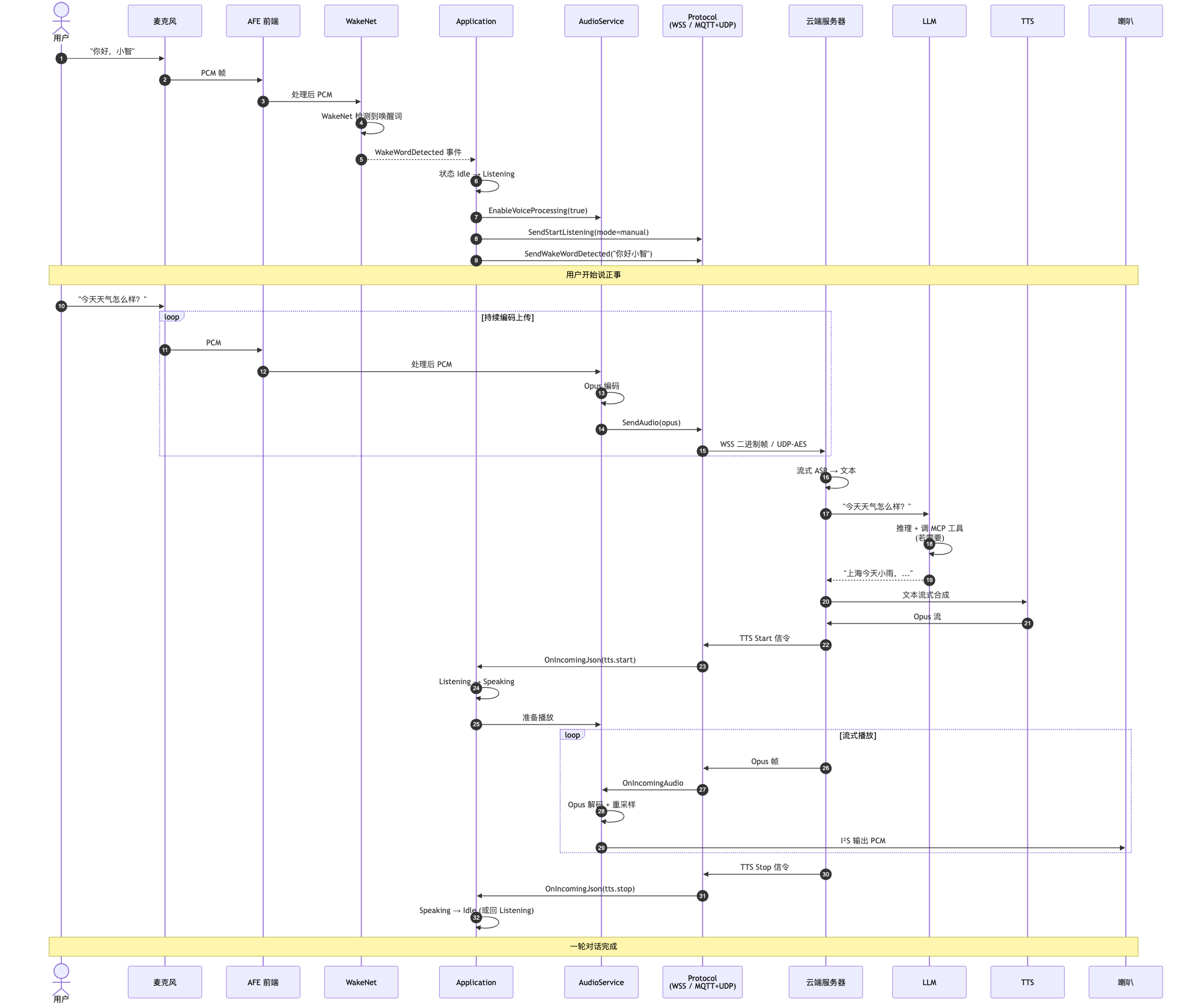
完整时序分 3 段
第 1 段:唤醒(约 200-400ms)
- 用户说"你好,小智"
- 麦克风采到 PCM
- AFE 处理(去回声、降噪)后送给 WakeNet
- WakeNet 检测到唤醒词,通知 Application
- Application 状态机:
Idle → Listening - 同时给云端发两条信令:
SendStartListening+SendWakeWordDetected
关键:唤醒词检测完全在设备本地跑(用 ESP-SR 的 WakeNet 模型),不需要联网。
第 2 段:上传 + 云端处理(约 800-2000ms)
- 用户继续说"今天天气怎么样"
- AFE 持续输出 PCM,Opus Encoder 编成 Opus 帧
- Protocol 把 Opus 帧通过 WebSocket(或 UDP+AES)发到云端
- 云端流式 ASR 把语音转文字
- 文字喂给 LLM,LLM 推理
- LLM 如果需要可以调 MCP 工具(比如查询设备位置、调用天气接口)
- LLM 输出"上海今天小雨,气温 18 度,建议带伞"
- 文字交给 TTS 流式合成 Opus
关键:整个过程是流式的——用户还在说,云端就已经开始 ASR;ASR 还在出文字,LLM 已经在推理;LLM 还在生成,TTS 已经在合成。延迟主要靠这种流式 pipeline 压下来。
第 3 段:播放回复(取决于回复长度)
- 云端发
tts.start信令 - Application 状态:
Listening → Speaking - 云端持续推 Opus 帧
- 设备 Opus Decoder 解出 PCM,重采样后塞给喇叭
- 一段话播完,云端发
tts.stop - Application 状态:
Speaking → Idle(单轮模式)或Speaking → Listening(连续对话模式)
关键时刻的"打断"
整个流程中用户随时可以打断:
- Speaking 期间用户喊一句话:AFE 仍在监测,VAD 检测到人声 → Abort → 立刻回 Listening
- Listening 长时间静默:超时 → 自动 Abort → 回 Idle
一句话讲清
"唤醒词本地识别保隐私 + 省功耗,识别到了就开始流式收声上传;云端的 ASR / LLM / TTS 全是流式串起来的,所以用户感受到的延迟很低;最后 Opus 流回来设备解码就播。任何阶段用户开口都能打断。"
关联章节
/04-audio§4.6(唤醒词触发)/02-main-application§2.6(HandleWakeWordDetectedEvent)/05-protocols(SendStartListening / 二进制音频帧 / 信令)